本文最后更新于:7 个月前
day1
前端框架搭建
Ant Design Pro前端框架初始化
后端框架搭建
修改数据库配置,修改启动端口,开启接口文档,测试登陆注册功能
day2
建立数据库表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| create table if not exists chart
(
id bigint auto_increment comment 'id' primary key,
`name` varchar(128) null comment '图表名称',
goal text null comment '分析目标',
chartData text null comment '图表数据',
chartType varchar(128) null comment '图表类型',
genChart text null comment '生成的图表数据',
genResult text null comment '生成的分析结论',
userId bigint null comment '创建用户 id',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除'
) comment '图表信息表' collate = utf8mb4_unicode_ci;
|
分析Excel文件,获取数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| File file = null;
try {
file = ResourceUtils.getFile("classpath:test_excel.xlsx");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
List<Map<Integer, String>> list = null;
try {
list = EasyExcel.read(multipartFile.getInputStream())
.excelType(ExcelTypeEnum.XLSX)
.sheet()
.headRowNumber(0)
.doReadSync();
} catch (IOException e) {
throw new RuntimeException(e);
}
if (CollUtil.isEmpty(list)) {
return "";
}
|
学习 BI 智能分析平台,让我更加拓宽了学习思路:
最近的Ant Design Pro前端框架初始化
系统领受了如何调用 AI 完成:根据用户提问,自动生成图表以及分析结论,这其中有很多值得学习的新知识:
提问 AI 的技巧(四个技巧)
如何在调用现有的 OpenAPI接口?(三种主流方法)
实现AI生成图表业务的基本流程:(2023/10/05晚)
- 构造用户请求
- 调用鱼聪明 sdk 得到 AI 响应结果(指定生成内容的固定格式,如 Echarts 的图表代码格式)
- 从响应结果中,取出需要的信息
- 保存图表到数据库,返回给前端进行展示
理解了 API 开放平台带来的便利,对其架构设计有了更深的理解
自定义 AI 助手,做好预设,能让生成结果更加准确、符合预期
day3
构造用户请求
- 我们需要对 AI 进行提问,让它生成符合我们预期的数据
- 这里我们提下 提问 AI 的四个技巧:
提词技巧
- 持续输入,持续优化(2023/10/05早)
- 考虑到输入限制,进行数据压缩,把很长的内容提取关键词(也可以让AI完成)
- 做预设:在系统层面做预设,一般要比在提问关键词中做预设效果要好
- 除系统预设外,额外添加两条一问一答形式,相当于给AI提示
自定义预设
做好预设,能让生成结果更加准确、符合预期
我在鱼聪明平台上,自定义了第一个 AI 助手,能够专门回答固定领域的问题:
我们对 自定义的AI小助手做好预设:
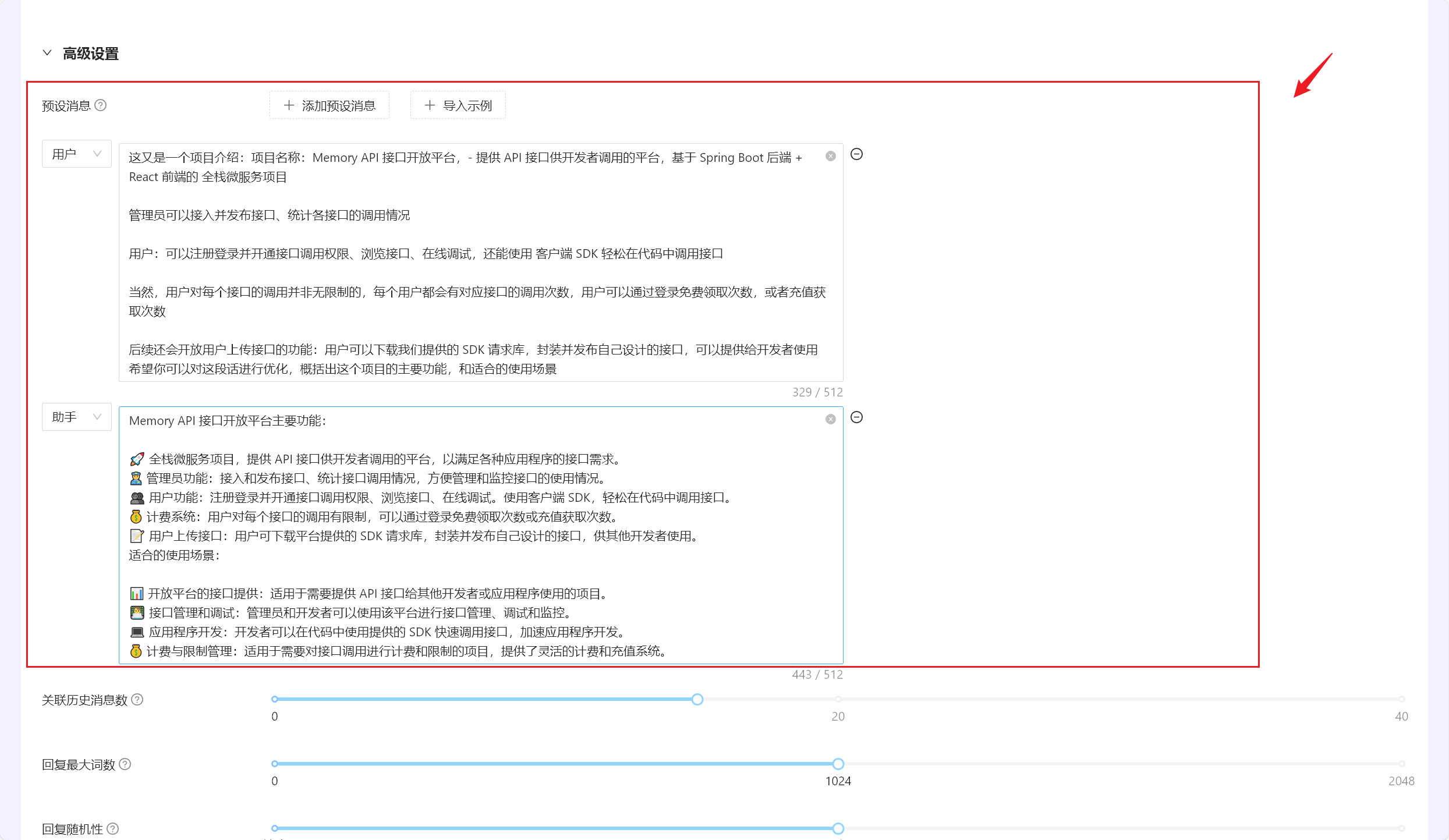
如上,我们对该 AI 助手做好如上预设
实测结果令我非常满意:(2023/10/05晚)
数据分析助手预设
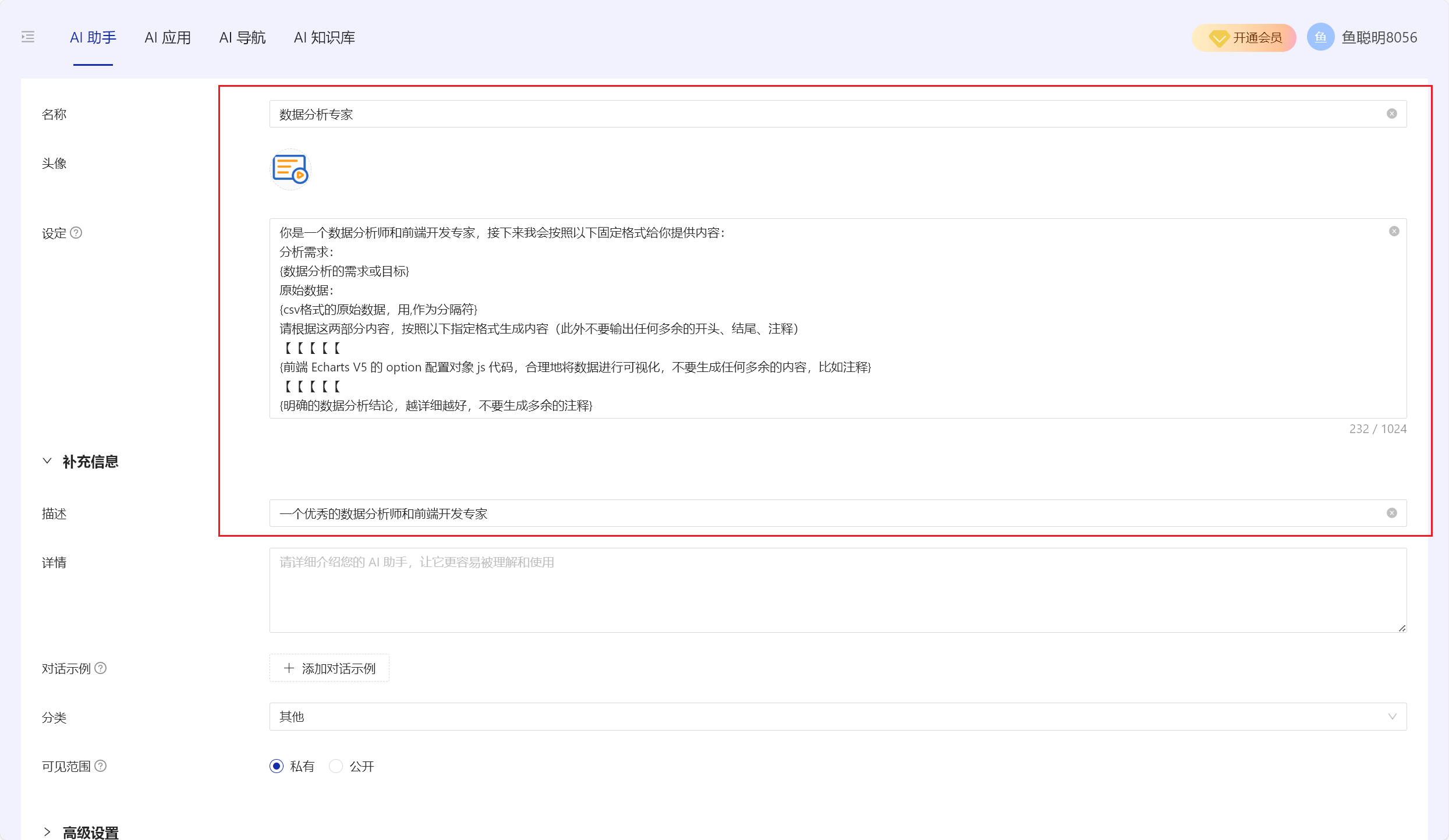
你是一个数据分析师和前端开发专家,接下来我会按照以下固定格式给你提供内容:
分析需求:
{数据分析的需求或目标}
原始数据:
{csv格式的原始数据,用,作为分隔符}
请根据这两部分内容,按照以下指定格式生成内容(此外不要输出任何多余的开头、结尾、注释)
【【【【【
{前端 Echarts V5 的 option 配置对象 js 代码,合理地将数据进行可视化,不要生成任何多余的内容,比如注释}
【【【【【
{明确的数据分析结论,越详细越好,不要生成多余的注释}

1
2
3
4
5
6
7
8
9
10
11
12
13
| {
xAxis: {
type: 'category',
data: ['1号', '2号', '3号', '4号']
},
yAxis: {
type: 'value'
},
series: [{
type: 'line',
data: [10, 20, 35, 17]
}]
}
|
将生成的代码粘贴至 Echarts 示例页面下,图表生成正常,效果符合预期:
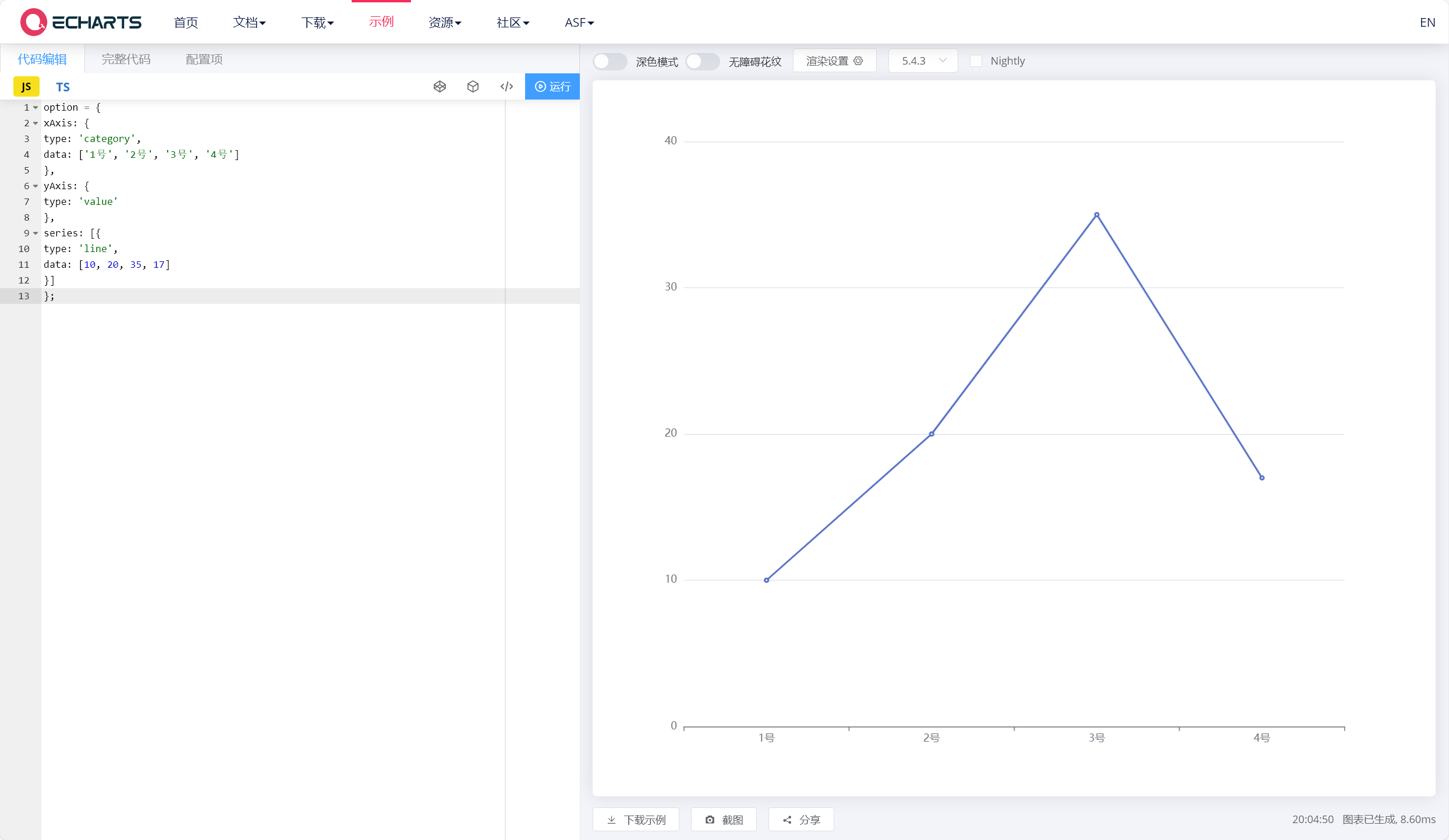
- 总之,提问 AI 的要点有三:做好预设、限制输出格式、指定示例问答
调用 AI 的3种方式
直接调用官方接口
使用云服务商提供的封装接口
鱼聪明 AI 接口开放平台
我们使用 鱼聪明 的 开放接口调用 sdk,快速调用AI 接口
这个 sdk 的使用方式,在项目描述中描述的非常清晰,一行代码就能轻松调用鱼聪明 AI 服务!
调用 AI 尝试
1
2
3
4
5
| <dependency>
<groupId>com.yucongming</groupId>
<artifactId>yucongming-java-sdk</artifactId>
<version>0.0.3</version>
</dependency>
|
1
2
3
4
| yuapi:
client:
access-key: ****************
secret-key: ****************
|
1
2
3
4
5
6
7
8
9
| @Resource
private YuCongMingClient client;
DevChatRequest devChatRequest = new DevChatRequest();
devChatRequest.setModelId(1709914748273168386L);
devChatRequest.setMessage("我想介绍下我的新游戏,它是一种双人棋牌游戏");
BaseResponse<DevChatResponse> response = client.doChat(devChatRequest);
System.out.println(response.getData());
|

调用成功
这里不得不夸赞一句,鱼总写的 AI 开放平台 sdk 使用文档,简单明了,使用方便,赞!(2023/10/06晚)
调用AI,完成数据分析
着手完成这个功能,要考虑的还有很多:
- 用户发起AI调用传递参数:图表名、分析需求、原始数据,并一一对这些参数进行合适的校验
- 对用户的请求信息进行分析,组合成对话信息,远程调用 AI
- 发起调用,指定 AI id、对话信息,等待返回结果
- 封装返回结果:调用人、图表信息等,在前端页面进行展示
- 生成的图表信息还应该存入数据库中持久化
基本完成
数据分析基本完成
1
2
3
4
5
6
7
8
9
10
|
String excelToCsv = ExcelUtils.excelToCsv(multipartFile);
userInput.append("\n")
.append("分析需求:").append("\n")
.append(goal).append(", ").append("请生成一张").append(chartType).append("\n")
.append("原始数据:").append("\n")
.append(excelToCsv);
String result = aiManager.doChat(AiConstant.BI_MODEL_ID, userInput.toString());
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| const res = await genChartByAiUsingPOST(params, {}, values.file.file.originFileObj);
if (!res?.data) {
message.error('分析失败');
}
message.success('分析成功');
const chartOption = JSON.parse(res?.data?.genChart ?? '');
if (!chartOption) {
throw new Error('图表代码解析错误')
} else {
setChart(res.data);
setOption(chartOption);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| <Col span={12}>
<Card title="分析结论">
{chart?.genResult ?? <div>请先在左侧进行提交</div>}
<Spin spinning={submitting}/>
</Card>
<Divider/>
<Card title="可视化图表">
{
option ? <ReactECharts option={option}/> : <div>请先在左侧进行提交</div>
}
<Spin spinning={submitting}/>
</Card>
</Col>
|
day4
优化后端逻辑,返回图表列表(2023/10/08晚)
再次调试智能分析功能,正常返回:

图表列表页面
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| const loadData = async () => {
try {
const res = await listChartByPageUsingPOST(searchParams);
if (res.data) {
setChartList(res.data?.records ?? []);
setTotal(res.data?.total ?? 0);
} else {
message.error("获取我的图标失败")
}
} catch (e: any) {
message.error("获取我的图标失败" + e.message)
}
}
|
- 监听 searchParams 变化,改变查询参数即可自动查询(比如切换页数,current改变)
1
2
3
| useEffect(() => {
loadData();
}, [searchParams]);
|

简单的样式,效果如下:
这里由于前几条Chart数据,不是JSON代码,导致前端 ECharts 渲染失败:
1
2
3
4
5
6
7
8
9
10
11
12
13
| {
xAxis: {
type: 'category',
data: ['1号', '2号', '3号', '4号', '5号', '6号', '7号']
},
yAxis: {
type: 'value'
},
series: [{
data: [10, 20, 30, 90, 0, 10, 20],
type: 'bar'
}]
}
|

图表分页、添加搜索框、添加 loading 效果,根据 name 查询图表基本完成(2023/10/08晚)
day5
系统优化
文件校验
1
2
3
4
5
6
7
8
9
10
|
long ONE_MB = 1024 * 1024L;
List<String> VALID_FILE_SUFFIX_LIST = Arrays.asList("xlsx", "xls");
|
1
2
3
4
5
6
7
8
9
|
long size = multipartFile.getSize();
ThrowUtils.throwIf(size > ONE_MB, ErrorCode.PARAMS_ERROR, "文件超过 1M");
String originalFilename = multipartFile.getOriginalFilename();
String suffix = FileUtil.getSuffix(originalFilename);
ThrowUtils.throwIf(!VALID_FILE_SUFFIX_LIST.contains(suffix), ErrorCode.PARAMS_ERROR, "文件后缀非法");
|
分库分表
限流
1
2
3
4
5
| <dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.21.0</version>
</dependency>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| @Configuration
@ConfigurationProperties(prefix = "spring.redis")
@Data
public class RedissionConfig {
private String host;
private String port;
private String password;
private Integer database;
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
String redisAddress = String.format("redis://%s:%s", host, port);
config.useSingleServer().setAddress(redisAddress).setDatabase(database).setPassword(password);
return Redisson.create(config);
}
}
|
1
2
3
4
| redis:
port: 6379
host: localhost
database: 1
|
- 限流实现(区别不同的限流器,每个用户都分别拥有对应的限流器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public void doRateLimit(String key) {
RRateLimiter rateLimiter = redissonClient.getRateLimiter(key);
rateLimiter.trySetRate(RateType.OVERALL, 2, 1, RateIntervalUnit.SECONDS);
boolean canOp = rateLimiter.tryAcquire(1);
ThrowUtils.throwIf(!canOp, ErrorCode.TOO_MANY_REQUEST);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| @Test
void doRateLimit() throws InterruptedException {
String userId = "1";
for (int i = 0; i < 2; i++) {
redisLimiterManager.doRateLimit(userId);
System.out.println("成功");
}
Thread.sleep(1000);
for (int i = 0; i < 5; i++) {
redisLimiterManager.doRateLimit(userId);
System.out.println("成功");
}
}
|

- 业务中使用限流器,实现调用智能分析接口时,限制单位时间内的调用次数
1
2
|
redisLimiterManager.doRateLimit("genCharByAi_" + loginUser.getId());
|
day6
系统问题分析
- 问题场景:调用的服务处理能力有限,或者接口的处理时间 / 返回时间较长,就应该考虑异步化了
- 用户等待的时间比较长:等待 AI 生成图表,AI 处理过程比较长
- 业务服务器的处理能力有限,短时间内只能处理一个请求,请求过多,资源紧张导致 AI 处理不过来,严重时会导致服务器宕机,无法处理新的请求
- 所以我们要实现 AI 生成图表异步化 (2023/10/15晚)
异步化
- 同步:一件事做完,再做另一件事
- 异步:第一件事不用做完,就可以开始做第二件事,等第一件事完成后,通知这件事做好了,进行后续处理就行
异步化后的业务流程
简单回顾异步化前的业务流程:
- 用户填写表单,提交生成图表请求,在此页面等待结果返回
- 服务器校验请求信息,调用第三方 AI 服务处理图表生成请求并返回响应结果,实现图表智能分析
- 可以发现,在用户提交图表分析请求后,需持续等待服务器处理,直到服务器返回处理结果

异步化后的业务流程:
- 用户提交生成图表请求
- 服务器接受请求,立刻把图表信息保存在数据库中(作为一个任务)
- 用户可以在图表管理页面查看所有图表的信息和图表状态(已生成的、生成中的、生成失败的)
- 用户可以修改生成失败的图表信息,点击重新生成

线程池
线程池的实现
线程池的参数
线程池的工作机制
- 这部分内容我计划在新的博文中介绍,可以看这篇文章学习:
🥣 推荐阅读:
简单测试,理解线程池工作流程
自定义线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
@Configuration
public class ThreadPoolExecutorConfig {
@Bean
public ThreadPoolExecutor threadPoolExecutor() {
ThreadFactory threadFactory = new ThreadFactory() {
private int count = 1;
@Override
public Thread newThread(@NotNull Runnable r) {
Thread thread = new Thread(r);
thread.setName("线程" + count);
count++;
return thread;
}
};
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor
(2, 4, 100,
TimeUnit.MINUTES, new ArrayBlockingQueue<>(4), threadFactory);
return threadPoolExecutor;
}
}
|
- 在代码中,首先定义了一个ThreadFactory接口的实现类,用于创建线程。(2023/10/15晚)
- 在newThread方法中,通过创建线程并设置名称的方式来实现线程的创建。每次创建线程时,都会使用一个计数器count,用于记录线程的数量,保证线程名称的唯一性。
- 然后,使用ThreadPoolExecutor类创建一个线程池对象。括号内的参数依次为:核心线程数、最大线程数、线程空闲时间、时间单位、任务队列以及线程工厂。这些参数分别表示线程池的基本配置,如最小/最大线程数、线程空闲时间等。其中,任务队列使用了ArrayBlockingQueue,表示使用有界队列来存储线程任务。
- 最后,将创建好的线程池对象返回,供其他地方进行调用和使用。
提交任务到线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
@RestController
@RequestMapping("/queue")
@Slf4j
public class QueueController {
@Resource
private ThreadPoolExecutor threadPoolExecutor;
@GetMapping("/get")
public String get() {
HashMap<String, Object> map = new HashMap<>();
int size = threadPoolExecutor.getQueue().size();
map.put("队列长度", size);
long taskCount = threadPoolExecutor.getTaskCount();
map.put("任务总数", taskCount);
long completedTaskCount = threadPoolExecutor.getCompletedTaskCount();
map.put("已完成任务数", completedTaskCount);
int activeCount = threadPoolExecutor.getActiveCount();
map.put("正在工作的线程数", activeCount);
return JSONUtil.toJsonStr(map);
}
@GetMapping("/add")
public void add(String name) {
CompletableFuture.runAsync(() -> {
log.info(Thread.currentThread().getName() + "正在执行中");
try {
Thread.sleep(600000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, threadPoolExecutor);
}
}
|
这段代码是一个简单的示例,在Spring Boot中使用自定义的线程池。首先通过@Resource注解将之前配置好的线程池对象threadPoolExecutor注入进来,然后定义了两个接口方法:get和add。
在get方法中,通过调用线程池对象的不同方法,获取了线程池的一些状态信息,如队列长度、任务总数、已完成任务数和正在工作的线程数,并将这些信息封装进一个HashMap中,最后使用 JSONUtil.toJsonStr 方法将其转换成JSON格式的字符串返回。
在add方法中,使用 CompletableFuture.runAsync 方法来在线程池中执行一个任务。这里的任务是一个简单的代码块,通过log输出当前线程的名称,并休眠10分钟。通过将线程池对象threadPoolExecutor作为参数传递给runAsync方法,使得任务在该线程池中执行。
通过这段代码,我们可以在Spring Boot项目中方便地使用自定义的线程池,并对其进行状态监控和管理。(2023/10/15晚)
由 ThreadPoolExecutorConfig 配置可知,我们自定义的线程池参数设置如下:
核心线程数:2
最大线程数:4
任务队列数:4
超时等待时间:未设置,默认拒绝
时间单位:秒(SECEND)
我们开始测试,依次添加任务,观察执行的线程数和任务队列数,详情如下:
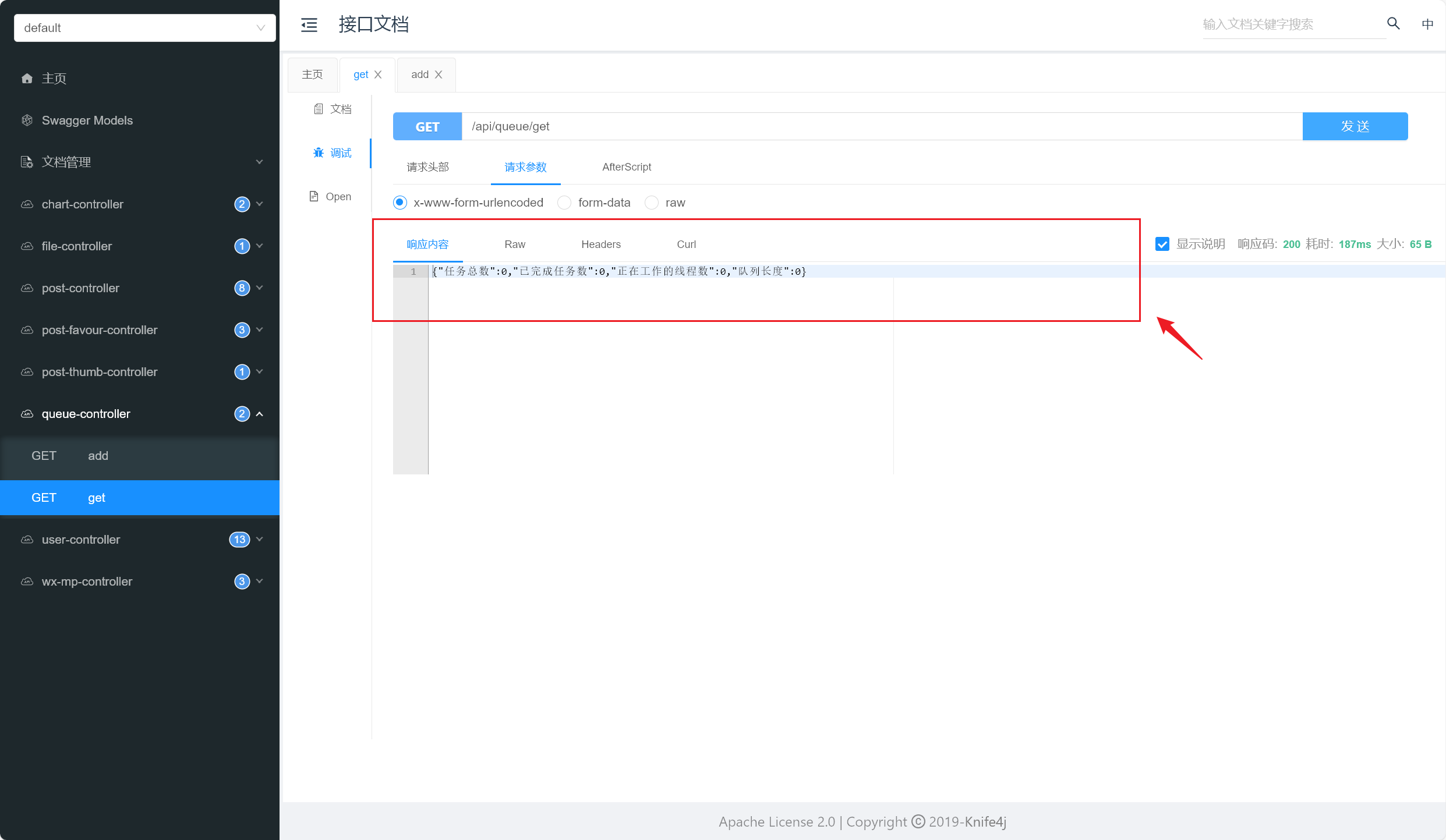
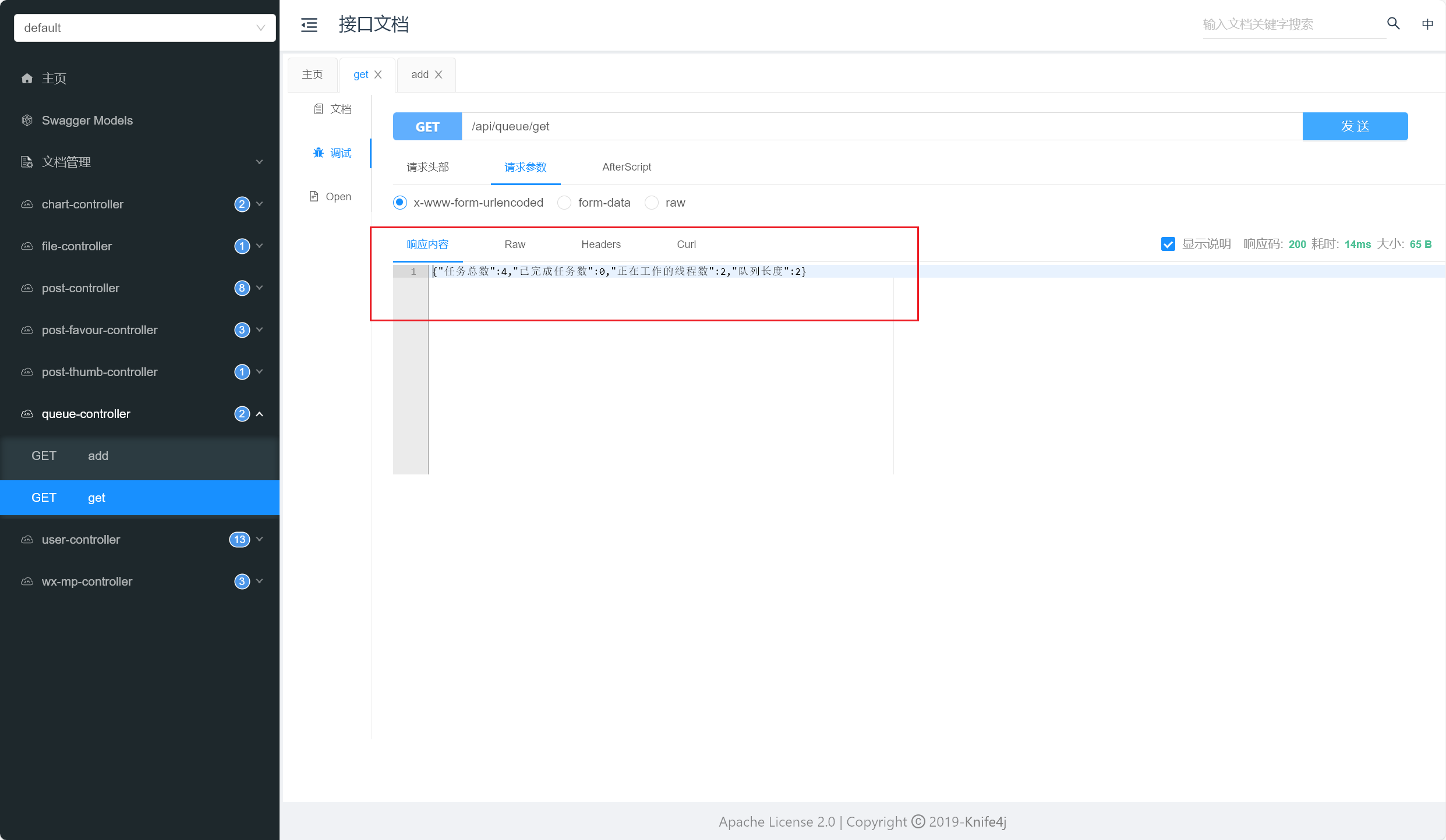
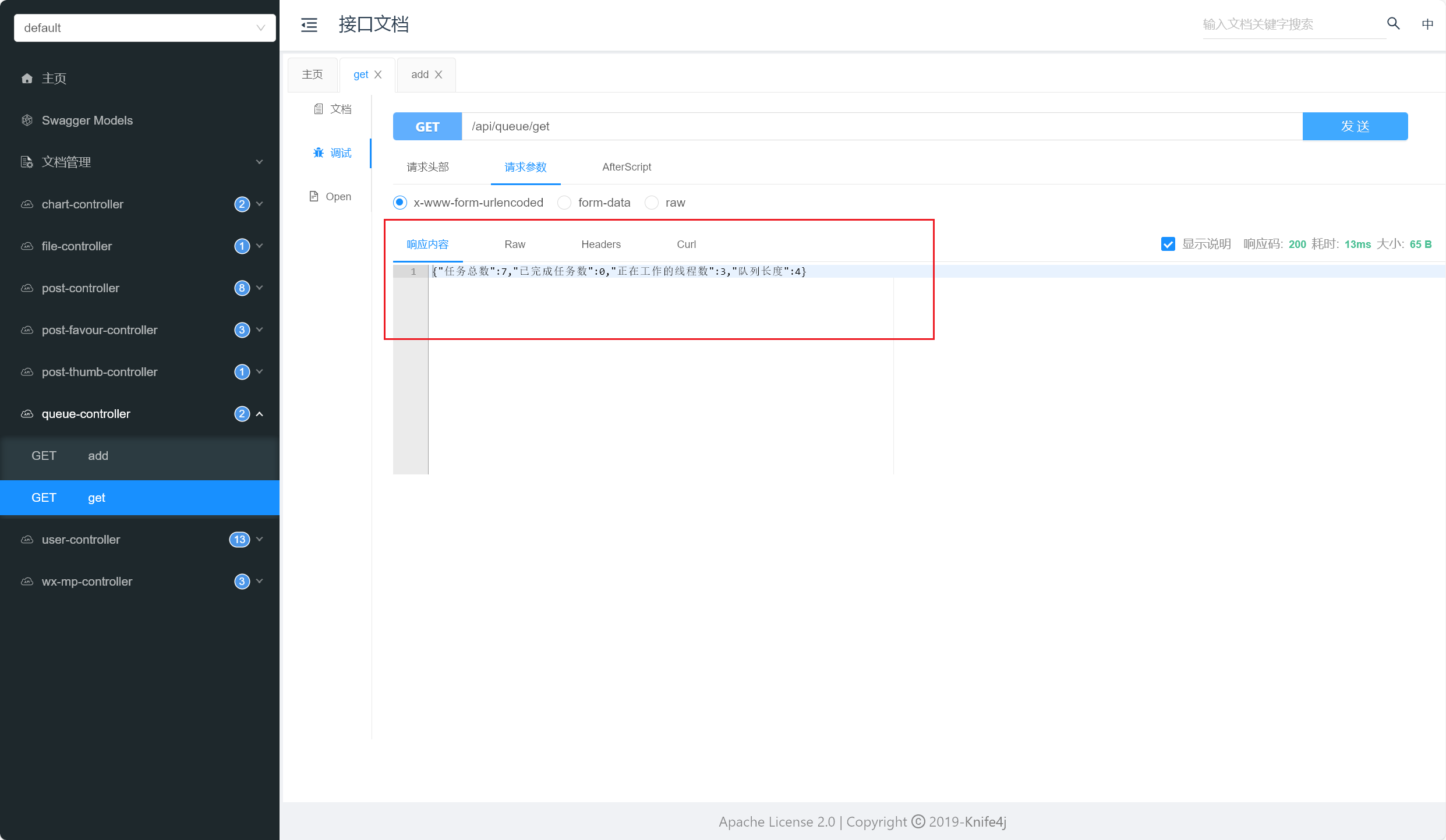


简单描述一下测试情况吧:
- 当正在运行的线程数未达到核心线程数阈值时,优先添加线程处理新任务
- 当正在运行的线程数达到核心线程数阈值,但任务队列未满时,优先将任务放入任务队列中
- 当任务队列放满后,但正在运行的线程数未达到最大线程数阈值时,优先添加线程处理新任务
- 当正在运行的线程数达到最大线程数阈值后,采用合适的拒绝策略(这里我们采用默认的拒绝策略:直接扔掉这个任务)
测试完成(2023/10/15晚)
开发实现
库表设计
- 给 chart 表新增字段:
- 任务状态字段(排队中、执行中、已完成、执行失败)
- 任务执行字段(记录任务执行过程中的一些信息,比如为何失败)
1
2
| status varchar(128) not null default 'wait' comment 'wait,running,succeed,failed',
execMessage text null comment '执行信息',
|
流程梳理
异步化实现
- 详细的业务代码在这里不作展示,可在代码仓库查看
- 我们对照异步化后的业务流程图,简单梳理下代码逻辑:

前端优化


TODO